There are a more mobile phone connections (~7.9 billion) than the number of humans (~7.7 billion) colonising this planet.
Let me explain.
Clearly, not every person in the world has a mobile device. Here we’re talking about mobile connections that come from people with multiple devices (dual SIMs, tablets) and other integrated devices like cars, and other smart vehicles, and of course the myriad IOT devices. I don’t have to go too far — my electric 2 wheeler has a mobile connection that it uses to cheerfully download the updated firmware version and the software patches every now and then.
While the global population is growing at 1.08% annually, the mobile phone connections are growing at 2.0%. We will very soon be outnumbered by the number of mobile subscriptions, all happily chatting, tweeting and in general sending data over the network. Some of it would need low latency and low jitter, while some may be more tolerant to the delays and jitter.
What’s the big deal with mobile connections growing?
Well, historically most people have used their mobile phones to talk; to catch up on all the gossip on your neighbours and relatives.
Not anymore.
Now, it’s primarily being used to watch video.
And lots of it; both cached and live.
And it will only grow.
Video traffic in mobile networks is forecast to grow by around 34 percent annually up to 2024 to account for nearly three-quarters of mobile data traffic, from approximately 60 percent currently.
Why is the mobile video traffic growing?
The growth is driven by the increase of embedded video in many online applications, growth of video-on-demand (VoD) streaming services in terms of both subscribers and viewing time per subscriber, multiple video sharing platforms, the evolution towards higher screen resolutions on smart devices. All of these factors have been influenced by the increasing penetration of video-capable smart devices.
India had (still has?) the highest average data usage per smartphone at around 9.8 GB per month by the end of 2018.
And the Internet traffic’s not even hit the peak yet.
It will hit the roof once 5G comes in. Will reach dizzying stratospheric heights when mobile content in the Indian vernacular languages comes of age.
India is home to around 19,500 languages or dialects. Every state has its own primary language and which often is alarmingly different from the state bordering it. There is a popular Hindi saying:
Kos-kos par badle paani, chaar kos par baani
The languages spoken in India change every few kilometres, as does the taste of the water.
Currently, most of the mobile content is in few popular Indian languages.
However, thats changing.
How is the Internet traffic related to the number of languages in India?
According to a Sharechat report, 2018 was the year when for the first time internet users in great numbers accessed social media in their regional languages and participated actively in contributing to user generated content in native languages.
A KPMG India and a Google report claims that the Indian language internet users are expected to grow at a CAGR of 18% vs English users at a CAGR of 3%.
This explains a flurry of investments in vernacular content startups in India.
When all these users come online, we are looking at a prodigious growth in the Internet traffic. More specifically, in the user generated traffic, which primarily would be video — again, video that is live or could be cached.
In short, we’re looking at massive quantities of data being shipped at high speeds over the Internet.
And for this to happen, the telco networks need to change.
From the rigid hardware based network to a more agile, elastic, virtualized, cloud based network. The most seismic changes will happen in the service provider network closest to the customer — the edge network. In the Jurassic age, this would have meant more dedicated hardware at the telco edge. However, given the furious rate of innovation, locking into rigid hardware platforms may not be very prudent since the networks will need to support a range of new devices, service types, and use cases. 5G with its enhanced mobile data experience will unleash innovation that’s not possible for most ordinary mortals to imagine today. The networks however need to be ready for that onslaught. They need to be designed to accommodate the agility and the flexibility that is not needed today.
And how do the networks get that agility and flexibility?
I agree with Wally for one.

The telcos will get that flexibility by virtualizing their network functions, and by, uhem, moving it all to the cloud.
Let me explain this.
Every node, every element in a network exists for a reason. It’s there to serve a function (routing, firewall, intrusion detection, etc). All this while we had dedicated, proprietary hardware that was optimized and purpose built to serve that one network function. These physical appliances had to be manually lugged and installed in the networks. I had written about this earlier here and here.
Now, replace this proprietary hardware with a pure software solution that runs on an off-the-shelf x86 based server grade hardware. One could run this software on a bare metal server or inside a virtual machine running on the hypervisor.
Viola, you just “virtualized” the “network function”!
This is your VNF.
So much for the fancy acronym.
The networks get that flexibility and agility by replacing the physical appliances with a telco cloud running the VNFs. By bringing the VNFs closer to their customer’s end devices. By distributing the processing, and management of data to micro datacenters at the periphery of the network, closer to the customer end devices. Think of it as content caching 2.0.
The edge cloud will be the first point of contact and a lot of processing will happen there. The telco giants are pushing what’s known as edge computing: where VNFs run on a telco cloud closer to the end user, thereby cutting the distance to a computer making a given decision. These VNFs, distributed across different parts of a network, run at the “edges” of the network.
Because the VNFs run on virtual machines, one could potentially run several such virtual functions on a single hypervisor. Not only does this save on hardware costs, space and power, it also simplifies the process of wiring together different network functions, as it’s all done virtually within a single device/server. The service function chaining got a lot simpler!
While we can run multiple VNFs on a single server, we can also split the VNFs across different servers to gain additional capacity during demanding periods. The VNFs can scale up, and scale down, dynamically, as the demand ebbs and flows.
This just wasn’t possible in the old world where physical network functions (fancy word for network appliances) were used. The telco operators would usually over-provision the network to optimize around the peak demand.
In the new paradigm we could use artificial intelligence and deep learning algorithms to predict the network demand and spin the VNFs in advance to meet the network demand in advance.
How can machine learning help?
Virtual Network Functions (VNFs) are easy to deploy, update, monitor, and manage. It’s after all just a special workload running on a VM. It takes less than a few seconds to spin a new instance of a VM.
The number of VNF instances, similar to generic computing resources in cloud, can be easily scaled based on load. Auto-scaling (of resources without human intervention) has been investigated in academia and industry. Prior studies on auto-scaling use measured network traffic load to dynamically react to traffic changes.
There are several papers that explore using a Machine Learning (ML) based approach to perform auto-scaling of VNFs in response to dynamic traffic changes. The ML classifiers learn from past VNF scaling decisions and seasonal/spatial behavior of network traffic load to generate scaling decisions ahead of time. This leads to improved QoS and significant cost savings for the Telco operators.
In a 2017 Heavy Reading survey, most respondents said that AI/ML would become a critical part of their network operations by 2020. AI/ML and Big data technologies would play a pivotal role in making real time decisions when managing virtualized 5G networks. I had briefly written about it here.
Is Telco Cloud the same as a data center?
Oh, the two are different.
Performance is the key in Telco Cloud. The workloads running on the Telco Cloud are extremely sensitive to delay, packet loss and latency. A lot of hard work goes into ensuring that the packet reaches the VNF as soon as it hits the server’s NIC. You dont want the packet to slowly inch upwards through the host’s (its almost always Linux) OS before it finally reaches the VM hosting the VNF.
In a datacenter running regular enterprise workloads, a few milli seconds of delay may still be acceptable. However, on a telco cloud, running a VNF, such a delay can be catastrophic.
Linux, and its networking component is optimized for general purpose computing. This means that achieving high performance networking inside the Linux kernel is not easy, and requires some bit, ok quite a bit, of customizations and hacks to get it past the 50K packets per second limit thats often incorrectly cited as an upper limit for the Linux kernel performance. Routing packets through the kernel may work for the regular data center workloads.
However, the VNFs need something better.
Because the Linux kernel is slow, we need to completely bypass the kernel.
One could start with SR-IOV.
Very simply, with SR-IOV, a VM hosting the VNF has direct access to subset of PCI resources on a physical NIC. With an SR-IOV compliant driver, the VNF can directly DMA (Direct Memory Access) the outgoing packets to the NIC hardware to achieve higher throughput and lower latency. DMA operation from the device to the VM memory does not compromise the safety of underlying hardware. Intel IO Virtualization Technology (vt-d) supports DMA and interrupt remapping and that restricts the NIC hardware to subset of physical memory allocated for a particular VM. No hypervisor interaction is needed except for interrupt processing.
However, there is a problem with SR-IOV.
Since the packet coming from the VNF goes out of the NIC unmodified, the telco operators would need some other HW switch, or some other entity to slap on the VxLAN or the other tunneling headers on top of the data packet so that it can reach the right remote VM. You need a local VTEP that all these packets hit when they come out of the NIC.
Having a VTEP outside complicates the design. The operators would like to push the VTEP into the compute, and have a plain IP fabric that only does IP routing. There was ways to solve this problem as well, but SR-IOV has limitations on potential migration of the VM hosting the VNF from one physical server to another. This is a big problem. If the VM gets locked down, then we lose on the flexibility and the agility that we had spoken of before.
Can something else be used?
Yes.
There’s a bunch of kernel bypass techniques, and I’ll only look at a few.
Intel DPDK (Data Plane Development Kit) has been used in some solutions to bypass the kernel, and then there are new emerging initiatives such as FD.io (Fast Data Input Output) based on VPP (Vector Packet Processing). More will likely emerge in the future.
DPDK and FD.io move networking into Linux user space to address both speed and technology plug-in requirements. Since these are built in the Linux user space, there are no changes in the Linux kernel. This eliminates the extra effort required to convince the Linux kernel community about the usefulness of the patches and their adoption can be accelerated.
DPDK bypasses the Linux kernel and manages the NIC and CPU assignment directly. It uses up some CPU cores for the network processing. It has threads that handle the receiving and processing of packets from the assigned receive queues. They do this in a tight loop, and anything interrupting these threads can cause packets to be dropped. That is why these threads must run on dedicated CPU cores; that is, no other threads — including the various Linux kernel tasks — in the system should run on this core.
Telcos consider this as a “waste” of their CPU cores. The cores that could have run the VNFs have now been hijacked by the DPDK to process packets from the NICs. Its also questioned if we can get a throughput of 100Gbps and beyond with DPDK and other kernel bypass techniques. It might be asinine to dedicate 30 CPU cores in a 32 core server for packet processing, leaving only 2 cores for the VNF.
Looks almost impossible to get 100Gbps+ thats needed for NFV.
Fortunately, no — things are a lot better.
Enter SmartNICs — the brainer cousin of the regular NICs, or rather NICs on steroids. These days there is a lot more brains in the modern NIC – or at least some of them – than we might realize. They take the offloading capabilities to a whole new level. The NIC vendors are packing in a lot of processors in their NIC ASICs to beef up their intelligence. Mellanox’s ConnectX-5 adapter card, which is widely deployed by hyperscalers has six different processors built into it that were designed by Mellanox.
Ok, so these are not CPUs in the normal sense, the ones you and I understand. These are purpose built to allow the NIC to, for instance, look at fields in the incoming packets, look at the IP headers and the Layer 2 headers and look at the outer encapsulated tunnel packets for VXLAN and from that do flow identification and then finally take actions.
This is history repeating itself.
Many many years ago, when dinosaurs still ruled the Earth, Cisco would use a MIPS processor to forward packets in software. And then the asteroid hit the Earth, and Cisco realized that to make the packet routing and forwarding more efficient and for it to scale, they needed custom ASICs, and they started making chips to forward packets.
This is exactly what is now happening in the Telco Cloud space. Open vSwitch was pure software that steered the data between individual virtual machines and routed it, but the performance and scalability was bad that companies started questioning on why some of the processing couldn’t be offloaded to the hardware. Perhaps, down to the NIC if you will. And thats what the latest and the greatest smartNICs do. You can download the OVS rules onto the NIC cards so that you completely bypass the Linux kernel and do all that heavy lifting in hardware.
DPDK and SmartNICs are very interesting and warrants a separate post, which i will do in some time.
So, what is the conclusion?
Aha, i meandered. I often do when I’m very excited.
The Internet traffic is exploding. It’s nowhere near the saturation point, and will increase manifold with 5G and other technologies coming in.
The Telco network can only scale if its virtualized, a’la the telco cloud. Pure hardware based old-style network, especially at the edges, will fail miserably. It will not be able to keep pace with the rapid changes that 5G will bring in. Pure hardware will still rule in the network core. Not at the edge. The edge cloud is where most of the innovation (AI/ML, kernel bypass in software, smartNICs, newer offloading capabilities, etc) will take place.
Telco cloud is possible. We have all the building blocks, today. We have the technology to virtualize, to ship packets at 100-200 Gbps to (and from) the VMs running the VNFs. Imagine the throughput that a rack full of commodity x86 servers, where each does 200Gbps, will get you.
I am very excited about the technology trendlines and the fact that what we’re working on in Nuage Networks is completely inline with where the networking industry is headed.
I am throughly enjoying this joyride. How about you?

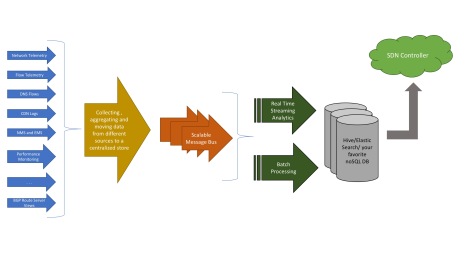 Flow telemetry and network telemetry will help in monitoring the traffic flowing inside the service provider networks. We could use this to gain a deep understanding of what a network looks like during normal operations and how it looks like when an anomaly is present in the network.
Flow telemetry and network telemetry will help in monitoring the traffic flowing inside the service provider networks. We could use this to gain a deep understanding of what a network looks like during normal operations and how it looks like when an anomaly is present in the network.
















