Internet, only a few weeks ago, had seen Pakistan Telecom Authority (PTA) hijacking the IP prefixes announced by Youtube, as protest against some videos that had been put up there, knocking millions off, all around the globe from accessing Youtube. I wrote about this here. This time its an ISP from USA and Europe, AboveNet (AS 6461) thats hijacked prefix announced and owned by Africa Online (AS 36915).
AboveNet inexplicably started announcing reachability to one of the prefixes (194.9.82.0/24) owned by Africa Online. It took AboveNet more than 22 hours since the problem was first reported, to fix it. Wonder what took them so long! As a result of this prefix hijack, potentially millions of users in Kenya or Africa, all behind 194.9.82.0/24, lost connectivity to the Internet. In isolation 194.9.82.0/24 is not a huge space, but add a couple of NATs and the number of users easily swells to millions. What this means for you and me, who are not being served by Africa Online is, that we lose connectivity to all the websites being hosted behind this IP address block. Imagine what it would do to the Internet if emergency services, banks, google were being hosted there!
Lets see why users in Kenya would lose total connectivity to the Internet:
A user accesses google.com with a (NATed or otherwise) source IP address 194.9.82.x. Google graciously responds, and the IP packet carries the destination IP 194.9.82.x. Because AboveNet has announced reachability to this IP address block, all traffic destined to 194.9.82.x comes to AboveNet where it gets royally dumped, while the user sitting in Kenya (or Africa) is still hopelessly waiting for the packet to arrive.
So, why are the service providers all over the world preferring the route announcement from AboveNet over the one originated from Africa Online?
Well, thats unfortunately how Internet, and my favorite routing protocol – BGP, works!
In BGP, the route advertisement from the provider which has a better vantage point on the Internet, usually wins.
In this particular case both AboveNet(AS 6461) and Africa Online (AS 36915) announced the route to 194.9.82.0/24 . AboveNet, operating from US, sits much closer to the core as compared to Africa Online, and is thus better connected to the other networks than the latter. The AS_PATH length thus seen by the other service providers for the route advertised by AboveNet is much shorter than the one advertised by Africa Online. As a result of this, other BGP speakers pick up the route advertised by AboveNet against the route advertised by Africa Online.
The figure below, constructed using BGPlay from RIPE NCC, shows a snapshot of the routing activity for 194.9.82.0/24 during the period when it was hijacked. The colored lines indicate the path different ASes would take to reach this prefix. Clearly most of the ASes believed AboveNet to be a better path for 194.9.82.0/24.
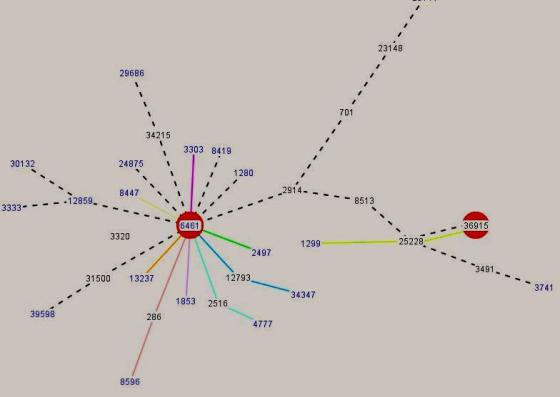
This is how BGP works and mind you, this isnt broken.
Whats broken is our inability to verify the claim of a service provider when it announces ownership of an address block in BGP. Restrictive route filtering can be applied where the providers only accept the specific prefixes allocated to the customers or where the upstream accepts only specific prefixes allocated to the ISPs, but this is too cumbersome and rarely works. As the matter stands today, there isn’t any clean way to know if the reachability announced by your friendly peer is genuine or whether the provider has a feasible path to the destinations advertised. This needs to be fixed and there is work going on towards this direction in the SIDR WG of IETF.
Can the service providers do something when they learn that an IP prefix has been hijacked by some AS? The answer, fortunately, to this is an unequivocal Yes.
A service provider can override BGP’s decision process in selecting the route advertisement with the shortest AS_PATH length by (i) manipulating the BGP path attribute like LOCAL_PREF since its checked before the AS_PATH length or (ii) decreasing the weight of the offending peer you learn the hijacked route from (this would only work for routers connected directly to AboveNet) (iii) Use regular expressions to filter all or the specific hijacked route advertisement from AS 6461 (AboveNet) so that the announcement from Africa Online wins. The legitimate route is now propagated to other parts of the world.
Each time an ISP inadvertently hijacks someone else’s address block it risks to lose some amount of credibility in the service provider world. Their names are splashed on the mails/PPTs in NANOG and IETF whenever there’s a discussion on interdomain security or on the blogs all over the world.
Fortunately for AboveNet, their hijacking didn’t throw millions off popular websites like Youtube, Google, Yahoo! etc. That would have attracted a LOT more attention than what this event did. When PTA had hijacked YouTube, it was all over the news and there were columns running in Wall Street Journal and New York Times about how tenuous the Internet architecture is. Also what unfortunately went in favor of AboveNet was that the affected users were not in US/Europe/Japan, but were in a relatively silent African subcontinent.



