For the sake of brevity i would refer an Intermediate System (IS) in IS-IS parlance as a router in the following post – thus a router in this post could mean either an OSPF speaker or an IS-IS speaker or some other routing element from your favorite link state protocol. For the SPF algorithm to work, it would require *all* routers in the network to know about all the other routers in the network and the links connecting them. How a link state routing protocol encodes this information and ensures that its disseminated properly is left to that protocol. OSPF encodes this information in Link State Advertisements (LSAs) and floods it reliably, while IS-IS encodes this in a Link State Packet (LSP) that it originates.
Once each router knows about all the other routers and the links connecting them, it runs the Dijkstra Shortest Path First algorithm to determine the shortest path from itself to all the other routers in the network. Since each router has a similar copy of the link state database and each runs the same algorithm, they end up constructing the same view of the network and packets get routed consistently at each hop.
So, how does SPF algorithm work in OSPF and IS-IS.
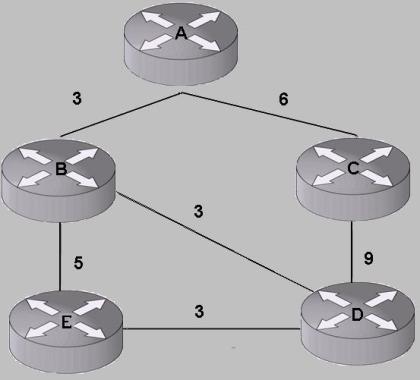
Imagine a simple network as shown in the figure below.
Once each router has flooded its link state information in the network, all routers know about all the other routers and the links connecting them. The link state database on each router looks like the following:
[A, B, 3], [A, C, 6], [B, A, 3], [B, D, 3], [B, E, 5], [C, A, 6], [C, D, 9], [D, C, 9], [D, B, 3], [D, E, 3] , [E, B, 5] and [E, D, 3]
Each triple should be read as {originating router, router its connected to, the cost of the link connecting the two routers}
So what does Router A do with this information and how is this used in SPF?
While running SPF, each router maintains two lists – the first is a list of nodes for which the shortest path has been determined and we are sure that no path shorter than the one we have computed can exist. This list is called the PATH (or PATHS) list. The second is the list of paths through the routers that may or may not be the shortest to a destination. This list is called the TENTative list, or simply the TENT list From now on, TENT would refer to the TENT list and PATH, to the PATH list.
Each element in the list is a triplet of the kind {endpoint router that we’re trying to reach, total distance from the calculating router, next-hop to reach the endpoint router}
Each router runs the following algorithm to compute the shortest path to each node:
Step I: Put “self” on the PATH with a distance of 0 and a next hop of self. The router running the SPF refers to itself as either “self” or the root node, because this node is the root of the shortest-path tree.
Step II: Take the node (call it the PATH node) just placed on the PATH list and examine its list of neighbors. Add each neighbor to the TENT with a next hop of the PATH node, unless that neighbor is already in the TENT or PATH list with a lower cost.
Call the node just added to the TENT as the TENT node. Set the cost to reach the TENT node equal to the cost to get from the root node to the PATH node plus the cost to get from the PATH node to the TENT node.
If the node just added to the TENT already exists in the TENT, but with a higher cost, replace the higher-cost node with the node currently under consideration.
Step III: Find the lowest cost neighbor in the TENT and move that neighbor to the PATH, and repeat Step 2. Stop only when TENT becomes empty.
Lets follow the sequence that Router A goes through for building its SPF tree.
1st Iteration of the SPF run
Step I: Put “self” on the PATH with a distance of 0 and a next hop of self. After this step the PATH and TENT look as follows:
PATH – {A, 0, A}
TENT – { }
Step II: Take the node (call it the PATH node) just placed on the PATH list and examine its list of neighbors. Patently, A is the PATH node. Examine its list of neighbors ({A, B, 3}, {A, C, 6}). OSPF does this by looking at the LSAs advertised by Router A, while IS-IS does this by looking at the neighbors TLV found in Router A’s LSP. When an IS-IS node is placed in PATHS, all IP prefixes advertised by it are installed in the IS-IS Routing Information Base (RIB) with the corresponding metric and next hop.
The Step II further says – “Add each neighbor to the TENT with a next hop of the PATH node, unless that neighbor is already in the TENT or PATH list with a lower cost.” A’s neighbors are B and C, and since neither of them is in the PATH or TENT, we add both of them to the TENT.
PATH – {A, 0, A}
TENT – {B, 3, A}, {C, 6, A}
Step II says – “Call the node just added to the TENT as the TENT node. Set the cost to reach the TENT node equal to the cost to get from the root node to the PATH node plus the cost to get from the PATH node to the TENT node.”
Lets pick up the TENT node B. The cost to reach B would be the cost to reach from root node to PATH node + cost from PATH node to TENT node. In the first iteration of SPF, both the root node and PATH node is A. Thus total cost to reach B is cost to reach from A (PATH node) to B (TENT node) which is 3.
Step II says – “If the node just added to the TENT already exists in the TENT, but with a higher cost, replace the higher-cost node with the node currently under consideration.”
B isnt in the TENT, so skip this.
Step III says – “Find the lowest cost neighbor in the TENT and move that neighbor to the PATH, and repeat“. The lowest cost neighbor is B (with cost 3). Move this to PATH. We go back to Step II since TENT isnt yet empty.
2nd Iteration of the SPF run
PATH – {A, 0, A} {B, 3, A}
TENT – {C, 6, A}
We have thus added the neighbor B in PATH, since we know that there cannot be any other shorter path to reach it. And this is, as you will note, consistent with our definition of PATH wherein we had earlier stated that nodes can only be placed there once we are sure that there cannot be any shorter path to reach them from the root node.
We begin our 2nd iteration and go to Step II which says – “Take the node (call it the PATH node) just placed on the PATH list and examine its list of neighbors“. B is the PATH node and we examine its neighbors (A, E and D). Step II further says – “Add each neighbor to the TENT with a next hop of the PATH node, unless that neighbor is already in the TENT or PATH list with a lower cost.”
Since A is already in PATH with ignore it and only add E and D to TENT.
PATH – {A, 0, A} {B, 3, A}
TENT – {C, 6, A} {D, 3, B}, {E, 5, B}
Step II says – “Call the node just added to the TENT as the TENT node. Set the cost to reach the TENT node equal to the cost to get from the root node to the PATH node plus the cost to get from the PATH node to the TENT node. ”
Aah .. this means that cost against D and E would not be 3 and 5, as what i have shown, but would instead be 3 (cost from A to B) +3 (cost from B to D) = 6 and 3 (cost from A to B) +5 (B to E) = 8
Thus the PATH and TENT look as follows:
PATH – {A, 0, A} {B, 3, A}
TENT – {C, 6, A} {D, 6, B}, {E, 8, B}
The rest of the Step II does not apply here since D and E dont exist in the TENT.
Come to Step III which says “Find the lowest cost neighbor in the TENT and move that neighbor to the PATH, and repeat Step 2″.
Lowest cost neighbor can either be C or D so pick on up randomly. It can mathematically be proven that we would end up with the same SPF tree irrespective of which equal cost neighbor is picked up from the TENT first. In our case, lets pick up C.
It is thus moved to the PATH
PATH – {A, 0, A} {B, 3, A} {C, 6, A}
TENT – {D, 6, B}, {E, 8, B}
3rd Iteration of the SPF run
Go back to Step II which says “Take the node (call it the PATH node) just placed on the PATH list and examine its list of neighbors. Add each neighbor to the TENT with a next hop of the PATH node, unless that neighbor is already in the TENT or PATH list with a lower cost”
C’s neighbors are A and D. Since A is already in the PATH only D is added in the TENT.
PATH – {A, 0, A} {B, 3, A} {C, 6, A}
TENT – {D, 6, B}, {E, 8, B} {D, 9, C}
As per Step II we now need to fix the cost to reach D from the root node. This would be cost to reach from A to C (6) + cost from C to D (9) = 15
PATH and TENT now:
PATH – {A, 0, A} {B, 3, A} {C, 6, A}
TENT – {D, 6, B}, {E, 8, B} {D, 15, C}
Step II further says – “If the node just added to the TENT already exists in the TENT, but with a higher cost, replace the higher-cost node with the node currently under consideration.”
node D already exists in the TENT (via B with cost 6) and since its with a lesser cost, we remove the node that we had just added from the TENT. This is because a lower cost path to reach node D already exists in the TENT.
PATH – {A, 0, A} {B, 3, A} {C, 6, A}
TENT – {D, 6, B}, {E, 8, B}
We come to Step III which says “Find the lowest cost neighbor in the TENT and move that neighbor to the PATH, and repeat Step 2″.
Lowest cost neighbor is D – which means we move D now to the PATH and go to Step II, since the TENT isnt yet empty.
4th Iteration of the SPF run
PATH – {A, 0, A} {B, 3, A} {C, 6, A} {D, 6, B}
TENT – {E, 8, B}
Step II says “Take the node (call it the PATH node) just placed on the PATH list and examine its list of neighbors. Add each neighbor to the TENT with a next hop of the PATH node, unless that neighbor is already in the TENT or PATH list with a lower cost.”
To examine D’s neighbors we look at the link state information it advertised. It advertised the following information:
[D, C, 9], [D, B, 3], [D, E, 3]
This means that D is says that its connected to C, B and E. We ignore its connection to B and C, since they are already in PATH. We thus only add neighbor E in the TENT.
PATH – {A, 0, A} {B, 3, A} {C, 6, A} {D, 6, B}
TENT – {E, 8, B} {E, 3, D}
Continuing with Step II which further says – “Call the node just added to the TENT as the TENT node. Set the cost to reach the TENT node equal to the cost to get from the root node to the PATH node plus the cost to get from the PATH node to the TENT node.”
This means that we need to adjust the cost of the triple {E, 3, D} that we just added to the TENT. The cost to reach E via D would thus be the cost to reach D from A (which is the root node) + the cost to reach E from D. This comes out to be 6 + 3 = 9.
TENT thus looks like this – {E, 8, B} {E, 9, D}
Step II further says – “If the node just added to the TENT already exists in the TENT, but with a higher cost, replace the higher-cost node with the node currently under consideration”
We just added node E in the TENT and a route to E already exists in the TENT, and its with a lower cost. This means that we remove the route that we had just added.
So PATH and TENT at this point look as follows:
PATH – {A, 0, A} {B, 3, A} {C, 6, A} {D, 6, B}
TENT – {E, 8, B}
We go to Step III which says – “Find the lowest cost neighbor in the TENT and move that neighbor to the PATH, and repeat Step 2″.
The lowest cost neighbor in TENT right now is E. We move this to PATH.
So PATH and TENT at this point look as follows:
PATH – {A, 0, A} {B, 3, A} {C, 6, A} {D, 6, B} {E, 8, B}
TENT – { }
Step III further states that we continue if and only if something remains in the TENT. TENT is now empty, which means that we have computed the shortest paths to all the nodes that A was aware of.
This is marks the end of the SPF algorithm run and the SPF tree that it has computed looks as follows